
This article was automatically translated. Read the original in french.
Since OpenAI launched its latest GPT chat baby on 30 November 2022, not a day goes by without seeing a post or article about the “phenomenon” that has managed to have a million users in 5 days. And since then, not a day goes by without Deeplink, a specialist in the field of human language understanding by Artificial Intelligence (AI), receiving a message or a call to ask me what’s up. So here is my point of view.
For Deeplink, Jérôme Berthier
In a few words, what is ChatGPT?
Quite simply, it is an application that allows the user to ask a question or a problem to an AI engine, and the latter, trained on a very large (but very large) corpus of data, generates an answer with a high linguistic level: without mistakes, neither spelling nor grammar, it answers coherent sentences with a content that is, a priori, sensible and correct in form.
If this sounds revolutionary, you should know that OpenAI is well known in the world of AI: they have been working for a long time on text generation algorithms (NLG – Natural Language Generation), playing with Google at a cost of billions. Moreover, behind OpenAI we find Samuel H. Altman (investors in AirBnB, Stripe, Reddit, Pinterest) as well as a certain Elon Musk. There’s also this little SME… Microsoft, which has injected a billion and is ready to put another billion back in, following the announcement that ChatGPT could generate a nine-zero income as early as 2024.
Beware of the buzz effect: ChatGPT is not Wikipedia or Google, let alone the truth. This is where you have to be very careful: the core of ChatGPT is built on GPT3, which is the system’s basic algorithm (hence the name). This text generation algorithm is based on a set of data retrieved from the web and from books (but the proportion is not known). It is a kind of auto-generated synthesis to which OpenAI has added a RLHF (Renfocement Learning With Human Feedback) mechanism in order to compensate for the absurdity of some of the generated content. This approach has the reputation of improving quality, but it is not infallible: not everything can be verified by a human, depending on who is verifying it, and on which corpus of data the information was taken from. This is also acknowledged by OpenAI themselves in their recommendations: ” ChatGPT sometimes writes plausible-sounding but incorrect or nonsensical answers.” On all these issues, OpenAI is not transparent and has not opened its databases to researchers to validate the model. The moral issue is not far away: data not verified by the academic world, managed by giants like Elon or Bill… in short, each one will make his own idea.
Does ChatGPT work?
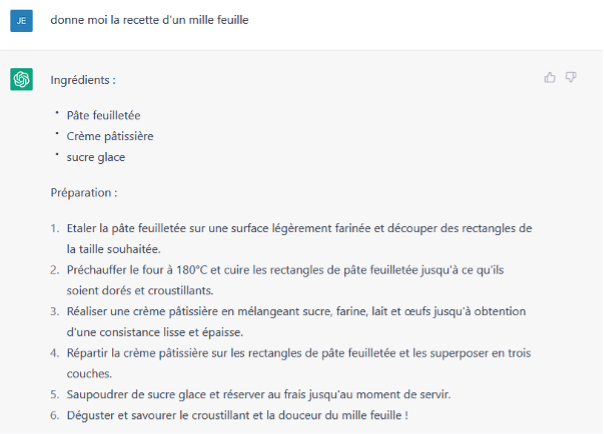
Yes, and no! We asked something simple to the algorithm: the recipe of a mille-feuille. As you can see in the picture, on the whole it looks right, it looks like it. But in reality it’s very rough, no dosage, no vanilla… and we challenge you to make a successful mille-feuille for a non pastry chef with this simple recipe. Here it is obvious to us, but ask yourself the question on a more complex theme..
For the sake of fun and for the sake of greed, we would love to receive photos of your mille-feuilles following strictly and only this recipe 😊.
So what’s the point?
Obviously, we have the right to ask ourselves what it’s for (and how OpenAI hopes to make 1 billion in revenue within 1 year)? First of all, ChatGPT is a technological feat and we must congratulate the OpenAI researchers for what they have achieved. The result is impressive.
We can see several immediate applications in ChatGPT:
- Easily populate content to post on social networks when you know the ins and outs of eMarketing and the need to feed your community.
- Create reports and assignments for students in need of inspiration
- Writing articles for uncritical newspapers
- Generating content for websites that no one reads but that are SEO friendly
But there is something fake about all these examples. Perhaps the real question is “how long will we be fooled”? In this sense, A. Turing was right with his test: doubting veracity, by questioning whether a text comes from a human or was generated by a machine, is the central element.
In my opinion, for ChatGPT to continue to shine, it would need at least three things:
- Transparency on training data for validation by the research and academic world
- Cross-referencing with fact-checking algorithms as for deep fakes
- A guarantee of data privacy. For the moment, everyone is playing with ChatGPT but no one cares where the data goes…
And at Deeplink, will we use ChatGPT?
This is a question that is being debated within the team. At first sight, for everything that is ancillary to the main themes of a chatbot (basically everything outside the scope for which our chatbots have been designed by our clients), ChatGPT could be very useful.
However, we will never use it for official answers that our customers give via our virtual agents because they have to be completely checked and verified by experts.
Imagine if the robot, to whom you ask a question about your parcel, starts telling you anything… Imagine an application from a canton that would give a random answer about obtaining a residence permit, or even worse, a medical application whose answer would not be perfectly mastered!
But then, is this a good thing, ChatGPT?
You know, I don’t think there are any good or bad things
As Otis would say, not so easy to answer. Because yes, it’s a nice technological advance and if we could only apply it to perfectly mastered data sets we could even make it very relevant. However we did a test that surprised us.

We trained our own human language understanding AI with sentences generated by ChatGPT. To our surprise, 100% of the sentences were recognised by our AI, where usually our AI understands between 80 and 90% of human generated sentences.
You might say this is good news! Maybe not. It’s just that it’s a bit puzzling when you consider the process of language processing by an AI. The AI translates each sentence into a mathematical vector after several transformations (decomposition into words, removal of punctuation, special characters, identification of the root of words, matching of synonyms in corpora of words of the same family). If two vectors are close, then the two sentences are talking about the same thing, and if not, the AI will look for other close vectors to determine what it is talking about. Hence the need for a lot of data.
For example, it is very easy for an AI to make the connection between “what is the sky like today” and “what is the weather like” because the terms are part of the same corpus of words: the weather. On the other hand, it has a much harder time matching “I’m a cuckold” and “I have such big horns that I can’t fit under doors”.
So what is it that frightens you about your test?
Maybe it was chance, but that 100% score caught our attention. If, as in our example, an AI generates so-called human sentences to train another AI to understand human language, wouldn’t the generation of these sentences already be biased, because they are based on mathematical algorithms and therefore perfectly understandable by another AI that has the same logic, in other words the same way of “thinking”?
In fact, if we take the concept to its logical conclusion, if humans delegated the learning of their own language to machines, wouldn’t the latter end up creating a kind of AI Esperanto that would become incomprehensible to humans and only to machines, thus serving no purpose?
Similarly, if an AI starts to generate texts for humans with its algorithms, are we not heading towards a standardisation of writing and an impoverishment of the language? The search for optimisation to please as many people as possible and computer assistance through algorithms in the world of car design have almost killed off eccentricity: cars all end up looking the same, with the same drifts: ever heavier, ever more equipped… and this is perhaps what awaits us for language if we are not careful.
The reflection can be generalised to the whole AI world when we also see the excitement in front of AI artists or the craze for the Metaverse..
However, let’s stay on a positive note, what the OpenAI engineers have done is a considerable advance in the field and we all have good hopes to see this type of algorithm made available to the computing community, as Google already does. And maybe some students will enjoy the snow more this Christmas, as their teachers will not yet be equipped with their red fact-checker pens 😉