
The following article was initially posted on Medium by Daniel Peppicelli. Read original.
On the bumpy road to build a love relationship advice chatbot
One day, my associate came to see me and told me: “I’ve been asked to create a chatbot proof of concept”.
The theme: love relationships.
After quite some analysis with a therapy specialist (since we’re not the best persons to go to for relationship advice), we decided that the bot should understand twelve of the most common relationship problems including breakups, jealousy (from the user or his/her partner), violence, sex, children, communication and relationship future.
The first NLP task on our end was clearly defined: Classify sentences such as “My girlfriend is crazy, she is going through my phone messages every evening” into the jealousy topic and sentences such as “I’ve been married for too long and I guess I need a change” into the “relationship future” category.
As for most of the machine learning tasks, we started by collecting data.
1. First try: scrapping the internet.
We went to psychology websites and looked for testimonies in the aforementioned categories. We cut them into sentences and manually classified the one that looked like genuine chatbot answers.
We ran that first dataset into an NLP classifier (the one of Rasa) and got descent results. So we moved one and used the trained classifier in our chatbot prototype.
When giving the chatbot to try to our friends, we realized that it was pretty bad at classifying their answers.
Lesson learned: You don’t write a testimony open to anyone on the Internet as you would speak to a chatbot…
2. Second try: Let’s collect data (and ask our wives)
Back to square one, we decided to collect data another way. We took time to write many versions of “I cheat on my wife”. We did the same with all the other categories.
We also asked our wives to do the same (as all of our friend were kind of tired of our chatbot).
As a result, we got a 1000 sentences dataset. We retrained our classifier and gave the chatbot another try. Still not working great…
Lessons learned: Well two things: 1000 sentences for 12 categories is clearly not enough. And since the sentences came from 4 persons with the same education level, the data was kind of biased.
3. Third try: Ask for (payed) help
We remembered from a Facebook research publication that they were gathering data using crowd sourcing platforms.
We went on these platforms to find out if they were offering tools to help this data collection. The only thing available was a spreadsheet like interface where we could ask people to enter data. Not the best way to put people in the context of a bot.
Fortunately, they also allows us to send a external polling link to their users ! Hurray !
So we wrote Chatbotstrap, which has now been renamed Deeplink. with the idea in mind to make it the “Doodle” of chatbot initial dataset gathering:
- Open the tool, define the intents that the chatbot should understand.
- Then design some mockup dialogs leading the user to the intent you want him to express.
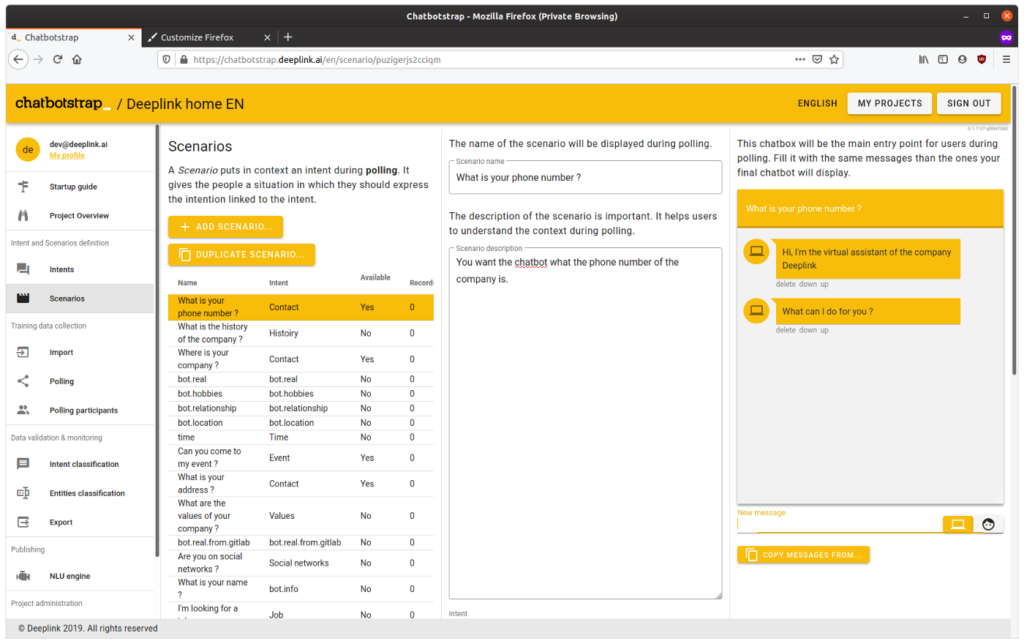
- Get a polling link, send it around (on Amazon Mechanical Turk, Clickworker, your friends, your colleagues, your students or your partner) and start receiving training sentences.
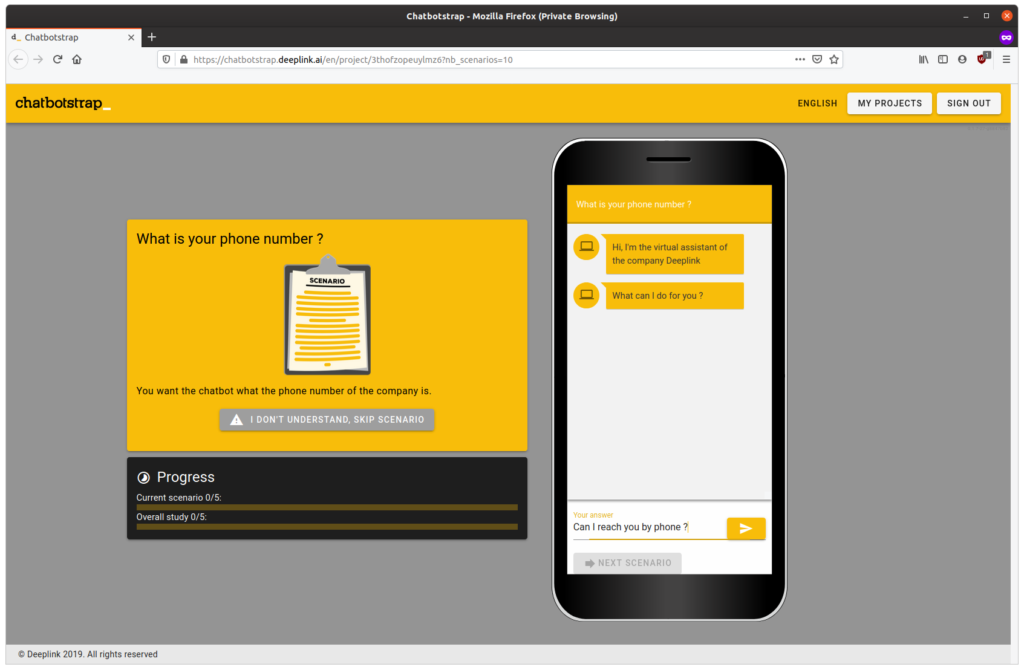
The very first use case of Chatbotstrap was our relationship chatbot. In a few days, we collected more than 4500 training sentences. The F1 score of our chatbot moved up from 0.55 to 0.75 and we were confident enough to demonstrate it to the client.
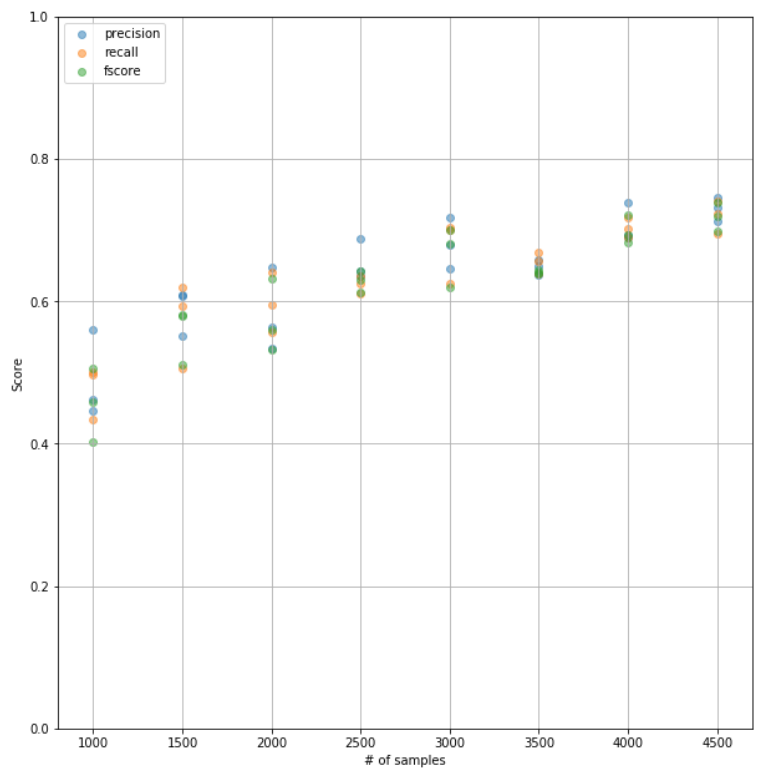
In conclusion
Unfortunately, the relationship chatbot project has been canceled. Nevertheless, we did rewrite Chatbotstrap to make it more than a one-shot tool and we used it on other projects (have a look at our company chatbot).
Feel free to try the Deeplink platform (free) if like us you are struggling to find proper initial training data for your bots (export in CSV, Rasa, Luis and Flair are available)