
In a landscape where artificial intelligence is constantly evolving, it’s becoming difficult to navigate. At Deeplink, we’re keeping a close eye on these changes. After several months of observation and internal testing, among the many new features, most of which were not practical, we identified and integrated the one that provided real added value: a new model to better meet our customers’ needs.
In the space of three years, generative AI has gone from being a curiosity to a tool used on a daily basis. It has established itself in the private sphere before gaining ground in businesses. In fact, ChatGPT is often opened before coffee is even drawn… but behind this now familiar presence, the uses are surprisingly restrained. As the NBER study shows, this adoption remains very measured: AI is mainly used to reformulate a text, translate, summarise, search for information or even ask for advice.
It is precisely here that we see a contrast with the evolution of the market. While usage is concentrated on a few essential tasks, the industry is pursuing a frantic race for raw performance, developing ever larger models.
Why do they do this? To feign human intelligence, a totally utopian quest at this stage, and without worrying about their energy consumption and operating costs.
“More is better”, is not a solution, as Yann LeCun reminds us, LLMs remain limited by nature: they do not understand the physical world, have no persistent memory and cannot plan or reason. So they are not destined to become general intelligences. On the other hand, they excel in their fundamental strengths: analysing, structuring, reformulating and generating text.
This is timely, as these skills are precisely what people use them for. A key question then arises: how can we objectively assess a model’s performance in relation to these needs?
Our selection criteria
AI users often have a very subjective assessment of their capabilities. This is why the scientific communities (both academic and industrial) have put in place objective and quantitative assessment criteria to compare models with each other. These criteria are based on scores obtained using “benchmarks” (standardised reference tests) designed to measure the “intelligence” and performance of models. Each new model is generally accompanied by the scores it has obtained in the main tests of the day.
Unfortunately, these test results do not reflect actual performance or usability in real-life industrialisation situations. By focusing on optimising these scores, designers can be led to make adjustments that ultimately undermine practical effectiveness.
In contrast, our evaluation method does not take account of these benchmarks alone. They complement our own decisive criteria, namely :
- Precision and accuracy in answering questions.
- Strict adherence to the instructions provided.
- Absence of hallucinations (see our article on this subject).
- Ability to ingest and understand large amounts of text.
- Multilingual proficiency in the national languages and the most commonly used languages.
- Precise and reliable execution of agentic processes.
Although the notion of “agentic “1 AI is still emerging, we include it in our benchmark as a criterion, because it brings new opportunities, complementing the simple conversational interaction between the user and the AI.
Evaluation and new model
On the basis of the criteria set out above and our experience of using it, we have decided to move from basing our models on Llama 3.1 to the open source Qwen 3 suite, without sacrificing security, confidentiality and, of course, exclusive hosting on Swiss soil.
Below are the results of our evaluation:
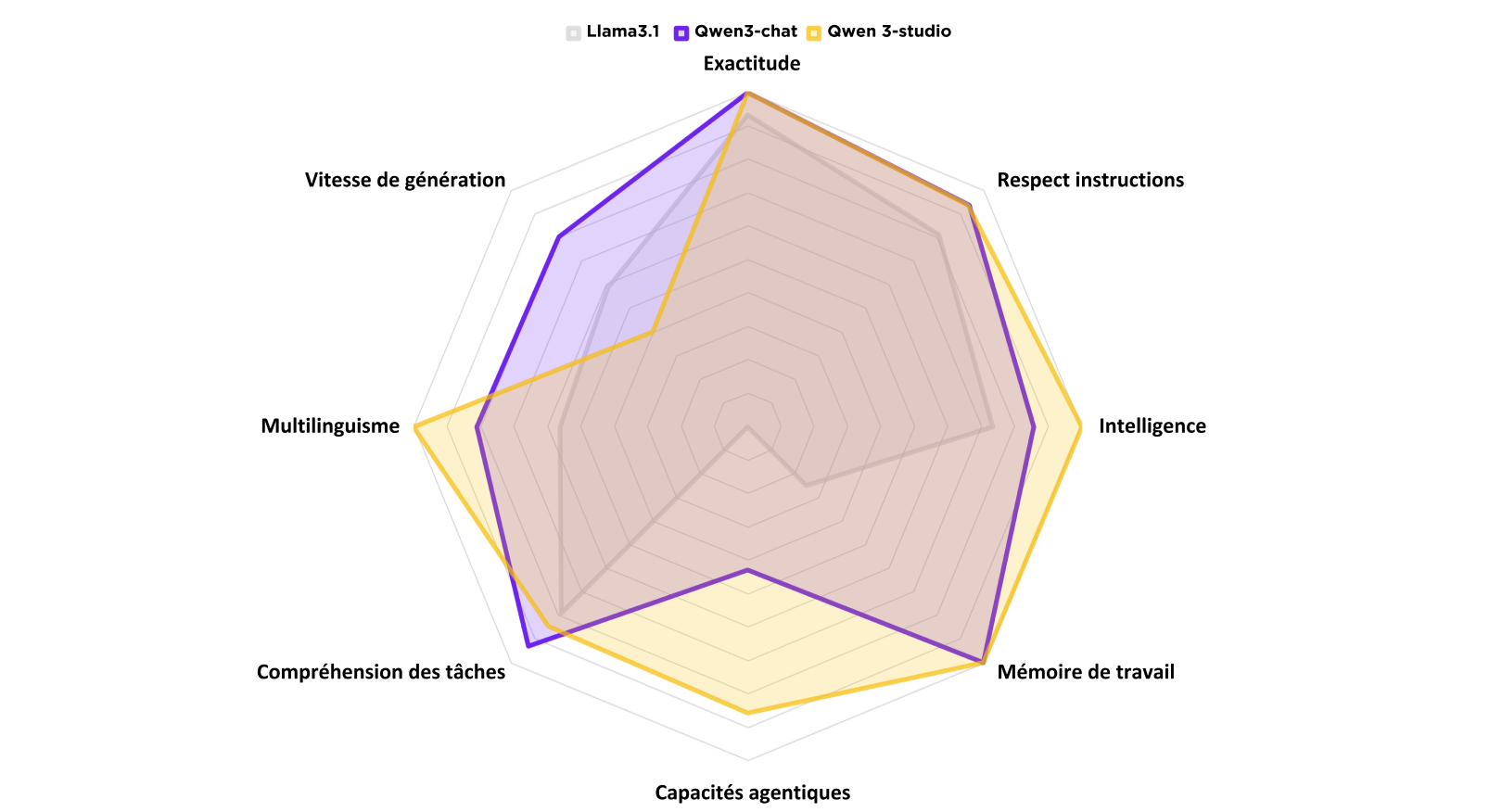
It’s worth noting that among the many advantages of this technical upgrade, it was the significant increase in memory that guided our choice. A larger memory directly benefits demanding tasks and document processing.
What about Apertus?
This 100% Swiss project represents an important initiative, not least because of the complete transparency of its data and training process. Its ambition is to provide a basis for high-performance models in the national languages and aligned with the country’s cultural specificities.
So what did we think? Despite the sometimes unrealistic expectations that may have surrounded this first version, we welcome the mission and the work that has gone into it. However, our tests show that it is not yet sufficiently competitive for general use in our tools, notably because of the limitations in its agentic use. This does not call into question its potential, and we are keeping a close eye on its development.
Keeping pace with advances in AI has become a real challenge, and that’s precisely why we’re stepping up to the plate. Our continuous monitoring enables us to identify, analyse and test new developments for our customers. This is an integral part of our mission: to provide them with the best tools, when they are mature and complete.
By working day in, day out with passion to become the innovation catalyst capable of extending your own R&D, Deeplink positions itself as your key partner. We are your guarantee of a true strategic ally to take full advantage of technological advances without ever losing sight of your business priorities.
- “L’IA agentique est un système d’intelligence artificielle capable d’atteindre un objectif précis avec une supervision limitée. Il se compose d’agents IA, c’est-à-dire de modèles de machine learning qui imitent les capacités humaines de prise de décision pour résoudre les problèmes en temps réel. Dans un système multi-agent, chaque agent exécute une sous-tâche spécifique pour atteindre l’objectif et leurs efforts sont coordonnés grâce à des fonctionnalités d’orchestration de l’IA.” IBM – Qu’est ce que l’IA agentique? ↩︎